2026年以来,AI算力、国产GPU等相关股票更是成为机构大资金的“心头好”。
5月18日,摩尔线程(688795.SH)发布公告称,贝莱德、摩根大通、富达国际、施罗德、柏基投资、GIC等多家海外头部基金,以及高瓴资本等千亿级私募,调研了公司。
部分顶级国际机构:
美国:贝莱德(管理规模13.9万亿美元)、摩根大通(管理规模4.2万亿美元)。
英国:施罗德(管理规模超7.6万亿人民币)、富达国际(管理规模超1.08万亿美元)、柏基投资(Baillie Gifford,管理规模约2.04万亿元人民币)。
新加坡:GIC(新加坡政府全资持有,管理规模9360亿美元)。
韩国:三星证券、未来资产金融集团(Mirae Asset Financial Group管理规模约7540亿美元)。
中东:阿曼国家储备基金(阿曼投资局管理规模约500亿美元)。
国内券商:中信证券、兴业证券。
基金和资产管理机构:汇添富基金、华安基金、南方基金、景顺长城基金,高瓴资本,东方红资产管理等。
摩尔线程到底有什么魔力,能让这群平时眼高于顶的国际资本如此“上头”?
当前,指数虽然迎来大幅回涨,5月13日,上证指数在4200点整数关口之上继续上涨,续创十年新高,但市场仍处在结构性修复阶段。科技成长相关行业持续突破,国内AI大模型技术持续迭代,token需求量激增,也让市场看到AI产业链打通商业闭环,并实质性兑现业绩的可能性。
同时,AI相关上市公司不断加大算力投入,全球半导体周期在高位进一步加速,叠加海外AI产业链大涨,对国内形成较强映射,像摩尔线程这样的龙头公司,自然成为资本关注的焦点。
全球知名的长期投资机构柏基投资对中国公司的投资规模是1807亿人民币。他们表示,“现阶段市场尚未充分定价人工智能、自动化与核心技术赛道本土领军企业的复利效应,这些企业五年内价值翻倍可期,兼具绝对价值安全边际与结构性增长带来的强上涨动能。”
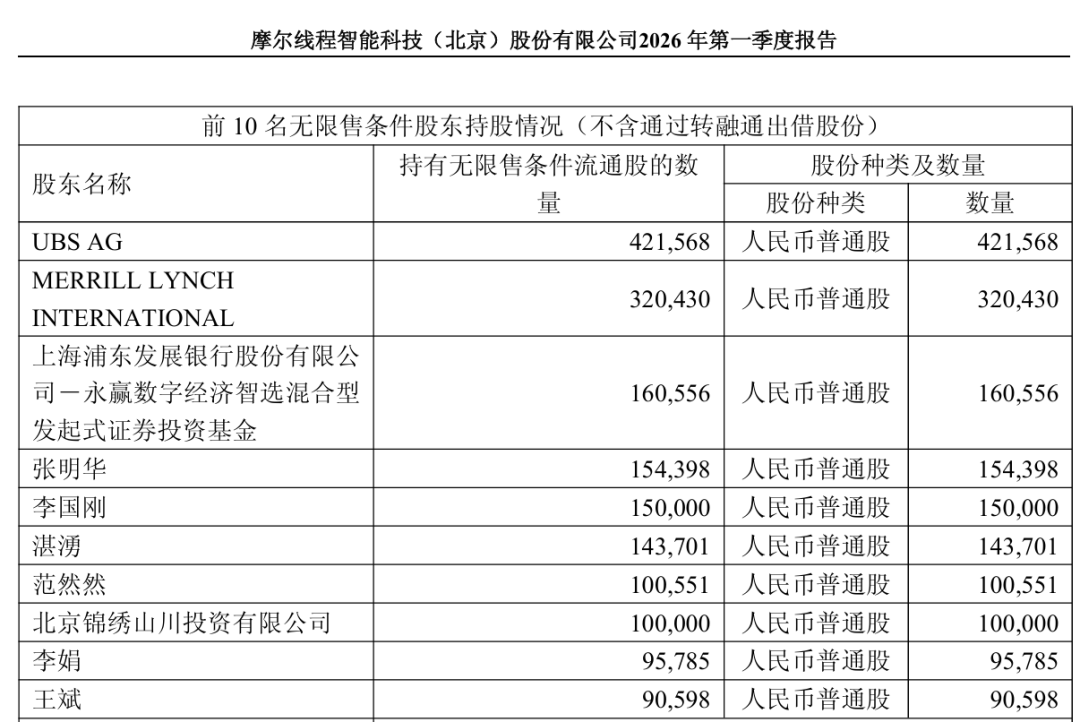
据摩尔线程2026年一季报显示,瑞银UBS AG和美林国际银行MERRILL LYNCH INTERNATIONAL现身前十名无限售条件股东行列:其中,UBS AG占公司股本比例0.09%,比2025年年报的0.06%增加了一半的持仓量;MERRILL LYNCH INTERNATIONAL占公司股本比例0.07%,比2025年年报的0.03%,增加了1.33倍的持仓量。
从调研内容看,机构关注焦点集中在公司高毛利的确定性、技术迭代进展、万卡集群交付与MUSA生态建设,看好摩尔线程在国产替代与AI算力浪潮中的成长确定性。
调研纪要如下:
1、能否解释一下公司通用全功能GPU架构理念,相比于业界将计算与图形分开的做法,我们为什么要把这些能力放在一起?
摩尔线程定位全功能GPU,公司基于自主研发的MUSA统一系统架构,率先实现了在同一颗芯片上同时支持AI计算加速、图形渲染、物理仿真以及超高清视频处理所需计算能力的突破,推动了我国GPU产业的自主可控进程,相比采用GPGPU、ASIC等技术路线的其他单一AI加速卡产品,MUSA架构技术具备更强的计算通用性、更优的技术演进能力、更高的生态兼容性以及更广泛的市场适应性。
在世界模型、具身智能、AI4S、物理AI等未来AI的发展趋势下,全功能GPU拥有更多的竞争优势,可适配未来更多的应用场景,满足多功能与全精度的需求,具有更大的灵活性和通用性。
2、对于CUDA的市场地位,以及兼容性的长期策略怎么看?
目前英伟达CUDA生态仍然占据绝对主导,一般而言,开发者或者客户从CUDA生态切换至新平台迁移成本高、适配工作量大。公司坚持既兼容主流又独立发展的策略,实现MUSA架构对CUDA生态高度兼容,旨在降低迁移门槛,减少双方人力与资源投入。
同时,公司通过自研MUSA开发平台,提供完整的开发、调试等工具,原生适配了PyTorch、vLLM、SGLang等主流框架,开发者可以基于原生MUSA架构开发新项目。目前公司开发者社区已经覆盖超过45万人,覆盖200多所高校,去年举办了首届MUSA开发者大会,今年还在快速扩张。
3、公司毛利率维持较高水平的核心原因是什么?
公司当前聚焦高性能训练市场为主,兼顾高质量的推理市场,该业务定位使得公司具备较高的技术门槛,拥有优质的客户结构与较低的市场竞争,从而支撑较高毛利率水平。
4、公司GPU产品是否可以适配市场上的主流模型?
公司产品已与业界主流SOTA大模型进行了Day0适配。公司依托 MTT S5000原生FP8能力与完善的MUSA软件生态,快速完成对DeepSeek V4、Minimax M2.7、GLM-5.1、中国移动九天大模型等的Day0适配。
5、公司如何看待训练与推理的差异?
训练市场更强调系统级平台的创新能力。目前以大模型厂商为代表的企业算法不断更新迭代,GPU厂商需提供通用、灵活的工具链以满足客户的需求,而摩尔线程全功能芯片具有更强的适应能力;推理市场则更关注性价比,当企业对于推理使用芯片产品需求量大时,可能会倾向于定制优化芯片性能。
推理市场的需求来源于终端用户交互,是对市场中已存在的模型进行应用,例如每天大量用户与大模型进行交互会消耗大量的词元(Token)。训练则是持续提升大模型智力水平的过程,技术门槛更高,每次训练大模型投入大。当大模型参数越多,数据量也会越多,所需算力水平呈指数增长。
6、公司在GPU互联通信方向的布局如何?
摩尔线程在GPU通信领域构建了自主可控的三层技术体系:芯片层面通过ACE异步通信引擎实现通信与计算物理级并行,减少15%计算资源损耗;卡间互联层面自研MTLink2.0技术,带宽性能高出国内行业平均水平,支持万卡以上规模集群扩展;生态标准层面深度参与中国移动OISA开放互联架构制定,并在下一代高密超节点引入对该标准的支持,将跨节点带宽推向TB/s级,为大规模智算中心提供了从芯片硬件到集群互联、从私有技术到开放标准的全栈解决方案。
7、公司当前的产品进展及下一代产品规划?
公司旗舰级训推一体全功能智算卡MTT S5000产品已量产并实现商业化落地,MTT S5000是国内为数不多的支持FP8精度的训推一体芯片。公司下一代的产品基于“花港”芯片架构,计划推出两款芯片:“庐山”面向高性能图形渲染,“华山”则专注AI训练与推理加速。
8、目前云边端同时进军,战略考量是什么?
公司的底层技术架构都是以全功能GPU为核心,以MUSA统一架构为基础。而面对未来AI赋能全场景的趋势,无论是云端、边缘端还是终端均会迎来全面爆发。
公司目前已构建起从云到端的产品矩阵,云端产品以训练为主,持续推进高性能国产GPU、先进互联网络、集群软件栈和算力调度平台的一体化布局,构建支撑万卡级、十万卡级智能算力集群的自主可控技术底座。在边缘与终端方向,加快推进SoC的迭代升级,围绕智能体和端侧推理发展趋势,前瞻布局端侧算力、轻量模型与软硬一体平台能力,推动终端设备从“可连接”向“可感知、可理解、可执行”的智能体载体升级。
此前,高盛发布了一篇摩尔线程的研究报告称,在技术迭代与行业景气度的双重驱动下,摩尔线程凭借通用GPU的全功能优势、全栈解决方案的场景覆盖能力及持续扩张的客户生态,正逐步在AI算力赛道占据重要地位。
未来,随着更多产品落地与生态完善,这家企业有望为中国AI产业的发展注入更强动力,也为半导体行业开辟新的增长空间。