2025年,对于国产GPU行业而言,已然成为决定生存根基、关乎竞争胜负的关键年份。
在国际博弈加剧与AI大模型爆发的双重压力下,国内业界形成了高度共识:缺乏自主可控的GPU算力,就无法在通往未来的科技竞争中占据一席之地。过去两年间,国内大模型企业一方面在全球范围内囤积算力资源,另一方面密集投资国内所有GPU厂商,全行业都在静待能够承载中国AI发展野心的领军者出现,期待国产芯片能在性能层面与国际巨头展开正面抗衡。
不过,这一行业格局在近期迎来了重要转折。12月20日,摩尔线程在北京中关村国际创新中心举办首届MUSA开发者大会(MDC2025)。会上,摩尔线程创始人、董事长兼CEO张建中在主题演讲中,正式发布最新GPU架构“花港”――该架构实现了50%的算力密度提升与10倍的效能飞跃。基于这一架构,摩尔线程同步推出两款核心芯片:面向高性能AI训推一体场景的“华山”芯片,以及专攻高性能图形渲染领域的“庐山”芯片。
据官方介绍,性能层面,华山芯片的访存容量已超越英伟达Blackwell系列,访存带宽则与之持平。尽管在绝对浮点算力与互联带宽上仍处于追赶Blackwell的阶段,但该芯片已在多个维度实现对长期占据行业标杆地位产品的超越。这种紧追旗舰产品的发展态势,标志着国产GPU已完成从“基本可用”到“顶级好用”的代际跨越。
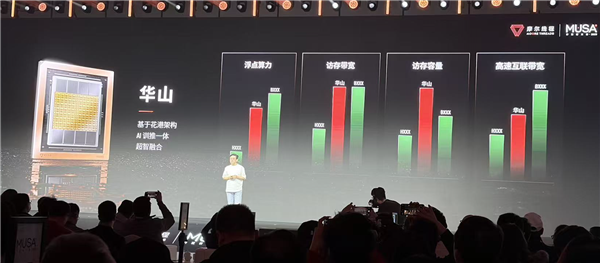
华山性能示意图|图片来源:极客公园
聚焦高性能图形渲染的庐山芯片,相较于上一代S80产品,能将3A游戏性能提升15倍,具体来看,其AI性能提升达64倍,光线追踪性能更是实现50倍增长。
作为国内少数敢于与英伟达正面竞争的GPU厂商,摩尔线程此次发布的全系列产品,进一步具象化了其“全功能GPU”的战略定位。目前,摩尔线程正联合生态伙伴,将算力应用场景逐步拓展至具身智能、生命科学、量子计算等前沿领域。
历经漫长的技术沉淀期,摩尔线程终于以“国产GPU第一股”的身份跻身行业聚光灯下。与此同时,市场的集中追问也随之而来:如何在激烈竞争中站稳脚跟?未来的发展路径将如何规划?尤为关键的是,在多款硬件产品落地后,其业务体系将如何构建?在芯片短缺与算力焦虑交织的行业背景下,摩尔线程这种全维度布局策略,能否在激烈竞争中挖掘到真正的“算力黄金”?透过此次大会释放的多维信号,我们得以清晰窥见这家企业重塑计算效率边界的雄心与实践路径。
一、一核架构、两类硬件、三款核心芯片的全栈布局
“算力即国力。我们期望从芯片到集群,以‘加速计算’能力为核心,依托全功能GPU打造国之重器。”摩尔线程创始人张建中在演讲中,阐述了其构建从微观芯片架构到宏观智算集群的自主突围路径。
与英伟达凭借CUDA生态构建竞争壁垒的逻辑相似,摩尔线程深刻意识到,单一硬件产品无法定义未来竞争格局,因此打造了纵深广阔的MUSA生态系统。该系统以集成AI计算、3D图形渲染、高性能计算与智能视频编解码功能的全功能GPU为核心,凭借全数据单元的兼容性,将算力延伸至科学计算、数字孪生、具身智能、量子计算、6G通信、生物医药等前沿领域。
在全功能GPU基础之上,摩尔线程构建了完善的硬件系统与软件支撑体系:硬件层面,其智算集群“夸娥”实现了从微型系统到十万卡规模的弹性扩展;软件层面,MUSA软件栈通过完备的加速库、调试工具及应用实例,为开发者提供从底层基础软件到AI训推系统框架的全闭环支持,甚至借助复杂的管理套件,攻克了超大规模系统运维的核心难题。
架构的持续迭代升级,是国产芯片抵御外部不确定性的核心保障。历经苏堤、春晓、曲院、平湖四代量产架构的技术积淀,摩尔线程计划于明年正式量产第五代架构“花港”。
该架构通过底层指令集升级实现性能空间优化,在同等工艺条件下,算力密度提升50%,能效提升10倍。同时,针对大模型发展趋势,摩尔线程专门优化了FP4、FP6、FP8等低精度计算单元,并支持十万卡以上集群的扩展需求。

花港架构|图片来源:摩尔线程
基于花港架构的AI芯片“华山”,创新性引入新一代异步编程模型,通过TCE-PAIR技术实现Tensor核心间的数据共享,将原本需两次调用的数据处理流程压缩至一次完成,从根本上解决了计算单元因任务分配不均导致的“空转”问题,在硬件底层实现了算子实际吞吐效率的优化。
此外,摩尔线程的技术突破不仅作用于数据中心领域,更在图形与边缘侧市场引发质性变革。承袭花港架构底层优势的专业图形显卡“庐山”,相较于前代S80,游戏性能提升15倍,AI原生算力激增64倍,几何处理能力提升16倍,并支持50倍性能提升的光线追踪硬件加速。通过统一任务引擎管理框架,“庐山”确保多核并行效率最大化,足以胜任CAD、CAE等高精度工业辅助设计任务。

庐山芯片|图片来源:摩尔线程
在连接云端与端侧的战略布局中,新一代AISoC“长江”芯片内部融合了CPU、GPU、NPU、VPU、DPU、DSP、ISP等多元异构引擎,赋予端侧设备极高的应用灵活性。目前,“长江”芯片可在高效率、低功耗的单芯片系统内,同时处理复杂逻辑指令与超高清视频编解码任务,覆盖从机器人到智能终端的全场景技术需求。

长江智能SoC芯片|图片来源:摩尔线程
为加速生态下沉,摩尔线程还推出售价9999元起的算力本MTTAIBOOK与个人工作站AICube,致力于将“云端算力”转化为“开箱即用”的个人生产力工具。
据介绍,MTTAIBOOK是首款真正意义上的“算力本”,其搭载长江SoC芯片,将大模型训推能力直接集成于便携设备之中。摩尔线程表示,通过内置的MTAIOS系统,开发者可在Linux原生环境下自由切换Windows虚拟机与安卓系统,实现从模型训练、推理调试到多端应用部署的全周期闭环。

MTTAIBOOK|图片来源:摩尔线程
针对个人开发者面临的环境配置痛点,AIBOOK提供了完善的预装方案,不仅支持Docker与深度神经网络库,还集成了VSCode、Python及PyTorch、vLLM等主流开发框架,配合1TBSSD与最高64G高速存储,使“一人一Agent”的设想成为现实。用户可借助其开放系统开发专属智能体,甚至让Agent接管系统操作,真正实现AI原生的工作流程。
如果说AIBOOK是流动的算力节点,那么AICube则是静默而强大的算力中枢。作为处于原型机阶段的小型工作站,AICube凭借强大算力成为家庭或办公室的“数据中枢”,通过人工智能交互实现对碎片化信息的智能化管理。无论是查询旅行照片、检索家庭短片,还是规划行程,其内置数字人均可作为“家庭大脑”提供即时服务。
算力竞赛的终极战场,终究是生态渗透率的比拼。为打破CUDA生态的惯性迁移壁垒,摩尔线程正在研发的MUSACode大模型已实现93%的自动化编译率,同时推进自研TexttoMUSA技术――通过自然语言直接生成代码,大幅降低开发者的生态迁移门槛。此外,GPU虚拟化技术的迭代实现了热迁移与热插拔功能,这一高可靠性特性显著增强了国产算力在云端部署的商业竞争力。
从华山、庐山到长江芯片,从数据中心到个人桌面终端,摩尔线程的全维度布局,彰显了其通过架构创新与软件深度重构,在现有制程框架下大幅提升计算效率的核心战略。
二、构建万卡AI超级工厂:重塑国产超算新上限
此前,万卡集群曾被视为行业难以逾越的技术高峰,但随着千亿级乃至万亿级参数大模型的涌现,构建自主可控的国产化超算底座,已成为全行业的共同追求。在此过程中,摩尔线程并不满足于单纯的芯片供应商角色,而是致力于打造一座智能化的“AI工厂”。
在大规模集群部署中,如何让数以万计的GPU实现类似单一大脑的协同工作,核心难题之一在于垂直扩展(Scale-up)效率。
为打破互联技术壁垒,摩尔线程的“华山”芯片不仅搭载高速MTLink4.0技术,还主动兼容多元化以太网协议,将国内合作伙伴的各类协议内置芯片之中。这一设计使华山芯片具备无缝适配广阔硬件生态的兼容性,让国产算力可通过跨厂商交换机实现自由扩展。目前,华山芯片的超节点垂直扩展能力已提升至1024卡,意味着超千颗GPU可在单一节点内实现极致带宽互通,为十万卡级超大规模集群的构建提供了物理基础。
然而,当算力规模迈向十万卡级别,系统稳定性便成为集群运转的生命线。摩尔线程通过RAS2.0技术,采用ECC与SRAM校验机制,使芯片能在故障发生瞬间自动完成检测、上报与故障单元精准隔离。这一设计确保了在成千上万芯片构成的集群系统中,局部微小故障不会引发系统性崩溃,让开发者与管理者可实时掌控集群健康状态,保障智算中心的安全性与业务连续性。
从2024年的千卡集群试水,到2025年万卡集群落地,再到未来十万卡级集群的规划,摩尔线程的夸娥智算集群正持续刷新国产算力的上限。这座位于北京的万卡智算工厂,不仅拥有10EFLOPS的惊人浮点算力,更在模型算力利用率与有效训练时长上取得突破――通过深度软硬件协同优化,其MFU(模型算力利用率)稳定保持在60%以上,从根本上解决了大模型训练中“出工不出力”的行业痛点。
显然,在摩尔线程的战略愿景中,国产超算绝非简单的硬件堆砌。为此,公司推出MTTC256超节点解决方案,实现256颗GPU在亿级拓扑互联下的高效互通;同时,为降低开发门槛,构建了从自研MTTransformer推理引擎到全面兼容vLLM、Llama.cpp等开源生态的完整软件矩阵。

MTTC256超节点解决方案|图片来源:摩尔线程
从华山芯片到夸娥智算集群,再到降低生态迁移门槛的MUSACode工具,摩尔线程正试图在制程瓶颈与技术壁垒构筑的行业迷宫中,开辟一条通往“算力自由”的中国路径,让国产智算中心真正成为支撑万物智能的核心基座。
三、对标英伟达?国产GPU的自主定义之路
当摩尔线程完整铺开其产品图谱,外界方能清晰感知这家企业在静默期内的深远布局。从苏堤、春晓、曲院、平湖架构,到即将量产的“花港”架构,一年一代的迭代速度,勾勒出国产算力持续攀升的发展曲线。从底层芯片逻辑来看,摩尔线程始终坚守“全功能、全精度、全产品业务”三大核心支柱。
此次大会现场,这一“全维度”战略意图展现得淋漓尽致:从云端智算中心到边缘计算节点,再到覆盖B端与C端的桌面终端,其纵贯产业链上下游的布局,几乎触及计算生态的每一个神经末梢。
推理生态层面,摩尔线程与硅基流动的深度合作,充分验证了其基础库的实战价值。数据显示,在Prefill阶段,单卡每秒可处理4000tokens;在Decode阶段,单卡每秒处理能力亦可达1000tokens。
不仅如此,摩尔线程在生命科学领域依托MUSA平台开发出Sponge与DSDP工具,着力培育生态原生应用场景;在前沿的AIFor6G赛道,与中关村联合合作,借助S5000芯片的算力优势,加速6G通信算法优化与网络部署,推动通信与算力的深度融合。
摩尔线程打造的数字人“小麦”,已开放核心能力,支持开发者在AIBOOK上原生开发2D数字人应用;同时提供云边结合的数字人制作工具,推动AI生成数字人在服务与交互场景的落地应用。
此次大会的一大亮点,是被置于各站台演示核心位置的MTTAIBOOK――这款产品已成为摩尔线程内部主力办公设备。后台参数监控显示,即便在播放高码率视频或多任务切换场景下,其底层全功能GPU的性能波动仍保持平稳。这一表现表明,AIBOOK并非浅尝辄止的“参考设计”,而是一款完成度高、瞄准真实市场需求的硬件产品。与之配套的个人数据中心产品AICube,这些消费级终端的试水,背后暗藏着摩尔线程下沉算力入口的战略野心。
摩尔线程打造的MTTAIBOOK和MTTAICube|图片来源:极客公园
然而,“全能布局”的背后,潜藏着业务重心取舍的难题。9999元的定价策略,也凸显出芯片厂商跨界进入终端领域的生态位风险。这种看似“战线过长”的布局,实则折射出国产GPU厂商在国际霸权生态下的集体困境。
在国际厂商生态壁垒坚不可摧、开发者使用习惯已然固化的当下,国产厂商的突围之路绝非仅凭单一芯片就能走通。现有成熟平台如同精密运转的钟表,所有外部组件均围绕其核心运转;而作为后来者的摩尔线程,必须亲自搭建适配平台、开发工具库、提供解决方案,甚至打造硬件终端。这是一种“为售芯片,先筑通路”的战略自觉――唯有提前打通全产业链通路,才能最大化释放国产芯片的性能优势,为自身争取进入核心赛道的入场券。
这一系列布局,最终凝结为摩尔线程前瞻且全面的业务体系。大会现场,不少行业人士将其称为“中国的英伟达”。诚然,从其公布的发展蓝图中,不难窥见其不甘追随、志在引领的雄心。但真正的破局者,从不满足于成为“另一个谁”。在技术封锁与生态挑战并存的当下,我们期待摩尔线程这套“以全破坚”的战略,不仅能为企业开辟生存空间,更能走出一条定义中国特色、通往算力自主的开拓之路。