来源 :开普云2026-03-13
近日,国家工业信息安全发展研究中心(赛昇实验室)发布权威评测报告,开普云旗下的开悟智能体平台在RAG能力、工作流能力、Agent工具调用能力三大核心维度的多项关键指标上,成绩优于主流厂商,为企业级AI Agent中台的技术标准提供了重要参考。
国家级权威测评,为AI Agent平台选型提供“避坑指南”
本次评测由具备CNAS和CMA双重权威资质的国家级专业检测机构——赛昇实验室组织实施,赛昇实验室是国家工业信息安全发展研究中心下设的专业检测实验室,为工业和信息化部直属事业单位。
评测严格遵循《大模型智能体开发平台通用能力测试规范》及国家标准(GB/T 45288.2-2025),通过统一的推理模型(DeepSeek R1/V3)、超过600个真实业务场景问题,结合多模态测试数据集、统一配置的智能体/工作流、综合性问题集,以及多样化调用与过程采集方式,实现对平台核心能力的系统测试与分析,所有参测平台的评估基于同一套公认的技术准则,排除了因评测标准不一导致的结论偏差,确保了评测过程的严谨性与结论的客观公正性,为企业AI中台选型提供了权威的“避坑指南”。
评测结果显示,开悟智能体平台不仅在基础能力上表现稳健,更在代表企业级复杂业务需求的高阶能力上实现突破,多项指标达到行业领先水平(SOTA,即当前最优)。
注:下表中行业平均水平数据来源于公开发布的《2025大模型智能体开发平台技术能力综合测试报告》。部分指标属于开悟智能体参与的扩展测试指标,其他厂商未进行该项指标评测。
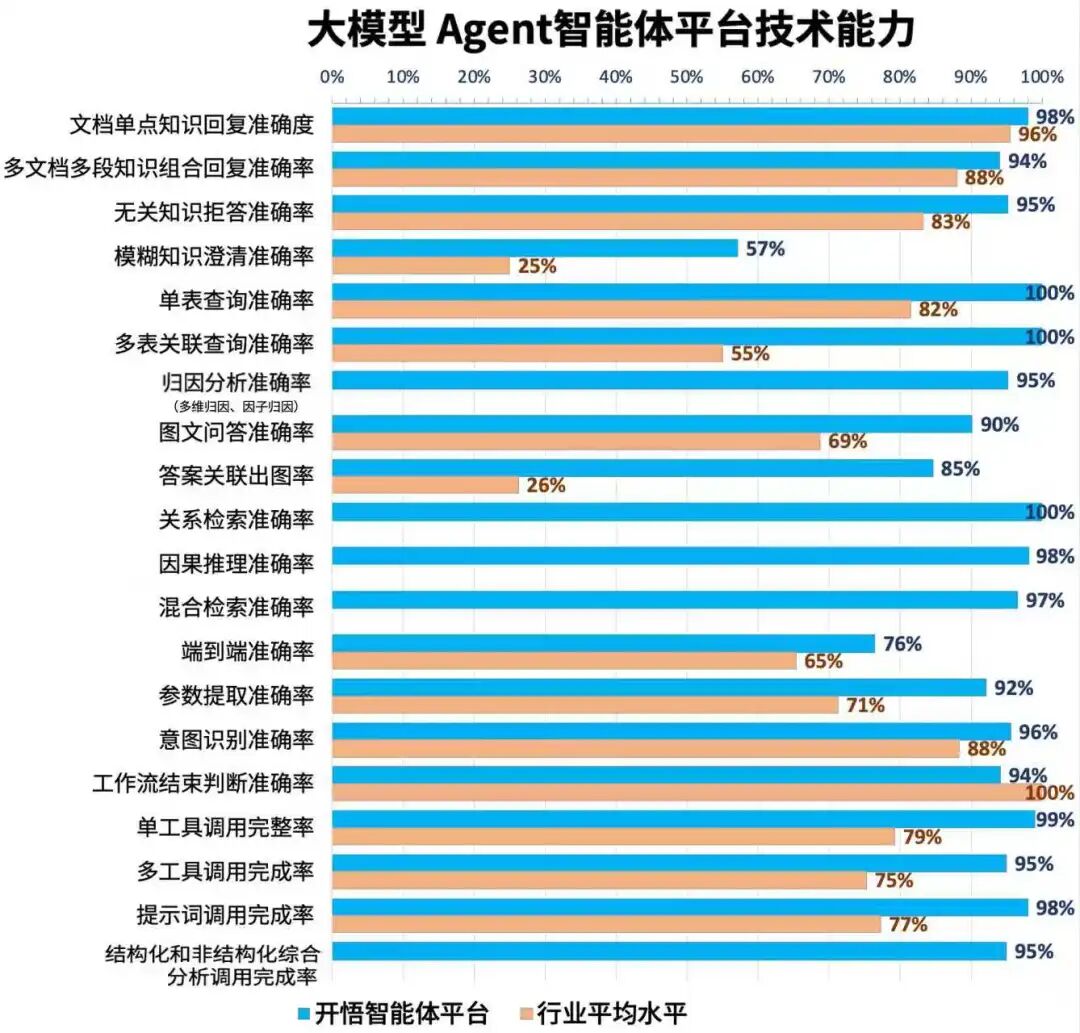
评测结果:三大核心能力全方位领先,定义行业SOTA新高度
第一,RAG能力:从“精准检索”到“深度推理”,实现知识深度赋能
在RAG能力测试的文本问答任务中,其文档单点知识回复准确率达98%,多文档多知识组合回复准确率达94%,无关知识拒答准确率达95%。在结构化数据问答任务中,平台实现了单表及多表关联查询准确率“双百”(100%)的突破,超过行业多表查询55%的平均水平;其独家参与的归因分析准确率亦高达95%。在图文问答任务中,平台以90%的问答准确率和85%的答案关联出图率,显著超过行业平均水平。
此外,作为唯一参与图关系RAG与混合RAG测试的平台,开悟在关系检索、因果推理、混合检索准确率上分别达到了100%、98%和97%,证明了其在多源异构知识融合与复杂推理方面的能力。
第二,工作流能力:破解长链路自动化瓶颈,保障流程稳定执行
工作流是实现复杂业务自动化的基石。评测从端到端准确率、参数提取、意图识别等维度综合评估平台的流程控制能力。面对行业普遍存在的长链路任务编排挑战,开悟平台表现优良:其端到端准确率达到76%,参数提取准确率高达92%,意图识别准确率达96%,均优于行业基准(分别为65%、71%、88%),工作流结束判断准确率也与头部水平持平。这充分证明了平台在复杂流程编排、精准意图理解和可靠节点执行方面的技术优势。
第三,Agent工具调用能力:精准执行,实现复杂任务智能闭环
Agent工具调用是开悟平台的核心优势领域,其各项指标均优于行业水平。在单工具调用、多工具顺序调用及基于提示词的工具调用中,平台完成率分别达到99%、95%和98%,大幅度优于行业平均水平(均低于 80%),展现出优良的任务分解、工具调度与结果整合能力。同时,作为唯一参与结构化和非结构化综合分析调用测试的平台,开悟以95%的完成率再次证明其成熟的异构数据融合与深度分析能力,能够直接满足企业级的复杂数据分析需求。
开普云开悟智能体平台以“混合知识增强检索+智能体工具链+自主规划引擎”为核心的技术架构,在此次国家级评测中展现了高准确性、强可控性与深度业务适配性的综合能力,成为构建下一代“企业AI大脑”的理想选择。未来,开普云将继续立足企业实际需求,持续优化技术架构与产品能力,推动AI智能体从技术创新走向规模化应用。