来源 :神州数码集团2026-05-08
2026什么资源最贵最稀缺?算力肯定算得上一份。高性能AI计算芯片主要供应商的全年产能早早锁定殆尽,高端AI服务器的交货周期从几周拉长到数月,价格同步走高;智能体应用的加速爆发,更是让每日Token消耗数以亿计,智能体集中应用的高峰时段,资源池分分钟“爆表”、“告警”。
这对正在加速AI落地的企业意味着什么?一句话:

面对这道行业难题,有没有一条不依赖新硬件就能突破算力瓶颈的路?
神州数码推出的HICA InfraOS给出了一份截然不同的答卷——
HICA InfraOS是什么?
| HICA InfraOS是神州数码自主研发的AI推理算力操作系统,以「统一算力调度层」为核心,将企业内分散的GPU资源纳入统一管理,覆盖从模型部署、请求调度、显存治理到全链路监控的端到端全生命周期。它既是运维团队的算力管控中枢,也是业务团队获得稳定AI服务体验的底层保障。适用对象:AI平台团队、基础设施运维工程师、技术架构师。产品形态:私有化部署产品,可融入现有K8s体系,无需替换原有基础设施。 |
从「用AI」到「管算力」:
企业场景下的AI算力困局
我们曾服务过一家大型集团,他们的故事,也是当下许多企业AI建设的缩影。
第一阶段:专注应用,算力“够用就好”
| 积极拥抱AI浪潮,该集团从很早的时候就决定全面推进AI化。智能周报、HR人才搜索、智能客服……基于不同业务场景的各类AI应用陆续上线。彼时该集团内部的运维团队精力投入和关注点,还重点在于把应用做好用,算力资源按需分配,每个业务线用自己的模型和GPU,互不干扰。这一阶段,一切都感觉还不错。 |
第二阶段:用户越来越多,AI开始“掉链子”
| 随着AI应用深入到日常工作,使用频率快速攀升。问题开始悄悄浮现—— ? 每逢月末、周五下班前,写周报的人一多,AI就开始“转圈圈”; ? 明明是简单的是非判断,却要等后面排着的大任务先跑完; ? 不同业务线各占一块GPU,有的空着,有的却撑不住。算力,开始成为制约AI体验的隐形瓶颈。 |
第三阶段:深度诊断,发现了什么?
| 面对日益明显的卡顿,神州数码的技术团队为该集团进行了一次系统性的算力审计。诊断结果触目惊心: ? 业务流量极不均匀:高峰时段的并发量是日常均值的7倍以上,系统几乎总是在两个极端之间摇摆; ? 请求类型天差地别:绝大多数是几十个字的简短判断,少数是耗时极长的长文生成——两类任务共用一套队列,长任务霸占资源,短任务干等; ? 重复劳动触目惊心:超过99%的请求都在复用同一套指令模板,但每次都要从头计算,算力白白浪费; ? 硬件潜力未被释放:虚拟化部署方案导致GPU卡间直连受阻,单机多卡场景下,硬件的真实性能有一大截被白白"卡住"; ? 小模型严重超配:Embedding、Rerank等辅助模型各自为政,每个业务线部署一份,GPU资源大量闲置。 |
神州数码HICA InfraOS算力操作系统
“四步破局”
面对该集团的“算力困局”,神州数码给出的建议并不是“再买几张GPU”这条老路。而是依托HICA InfraOS,让每一张已有的GPU都物尽其用。
具体怎么做?四步棋,环环相扣。
第一步 给AI铺一条专属高速公路
(硬件底层解锁)
| 虚拟化环境就像在四车道公路上强行划出隔离带——表面是多条车道,实则互相堵塞。神州数码基于HICA InfraOS算力操作系统,从BIOS层开始动刀,拆掉隔离,让GPU卡与卡之间真正实现直连高速传输,把被虚拟化“卡住”的那部分算力全部释放出来。硬件该有的性能,一分不少地应用于业务场景。 |
第二步 让每个请求都找到最合适的GPU
(智能调度+优先级保障)
| 传统负载均衡像轮流排班的收银台——不管顾客买多买少,一律排队。HICA InfraOS的调度系统则“更聪明”:它知道哪个GPU“记忆”里存着本次请求最需要的上下文,于是直接送过去,跳过重复预热。更关键的是,它支持“VIP插队”——紧急的高优先级任务,最多等一个计算步骤就能抢到资源,不再被长任务死死堵住。关键业务的响应,不再受慢任务拖累。 |
第三步“背过”的题,不用再算第二遍
(推理加速+Prefix Cache)
| 事实上,细细分解实际业务场景,神州数码技术团队发现,超过99%的AI请求都在用同一套指令开头。这就像考试前背过的公式——每次都从头推导,纯属浪费。于是,技术团队基于HICA InfraOS开启前缀缓存,把这些重复的“开头”存下来,下次直接调用;同时引入投机解码技术,用小模型先“猜答案”、大模型快速验证,让AI的输出速度成倍提升。重复的算力开销大幅削减,首字生成速度显著提升。 |
第四步 按需分配“内存”,告别“大锅饭”
(精细化显存治理)
| 该集团原来的算力调配做法像是“大锅饭”——不管模型大小,GPU内存一律按最高需求预留,小模型也占着大块地方。神州数码技术团队基于HICA InfraOS为三类模型(Encoder型、弱KV缓存型、强KV缓存型)分别制定显存策略,像“量体裁衣”一样精准分配。释放出来的空间,用于承载更多并发请求,而不是白白闲置。同样的GPU,能做的事翻倍。 |
数据说话:
真实生产流量验证成效
神州数码的算力方案,在该集团真实的生产压力测试下,效果显著——两周完整生产日志,按原始请求顺序、原始并发节奏逐条重放,3倍峰值压力下的结论同样成立。
1
整体算力配置:
用更少的卡,做同样的事

2
大模型推理优化:延迟砍掉近一半,
极端压力下依然稳如磐石

3
小模型集群:精细治理显存,
GPU减半、性能翻倍
神州数码依托HICA InfraOS为该集团建立了精细化的显存分类治理体系,针对Encoder、弱KV Cache、强KV Cache三类模型分别制定专属分配策略,精准核算显存占用,大幅削减冗余预留。

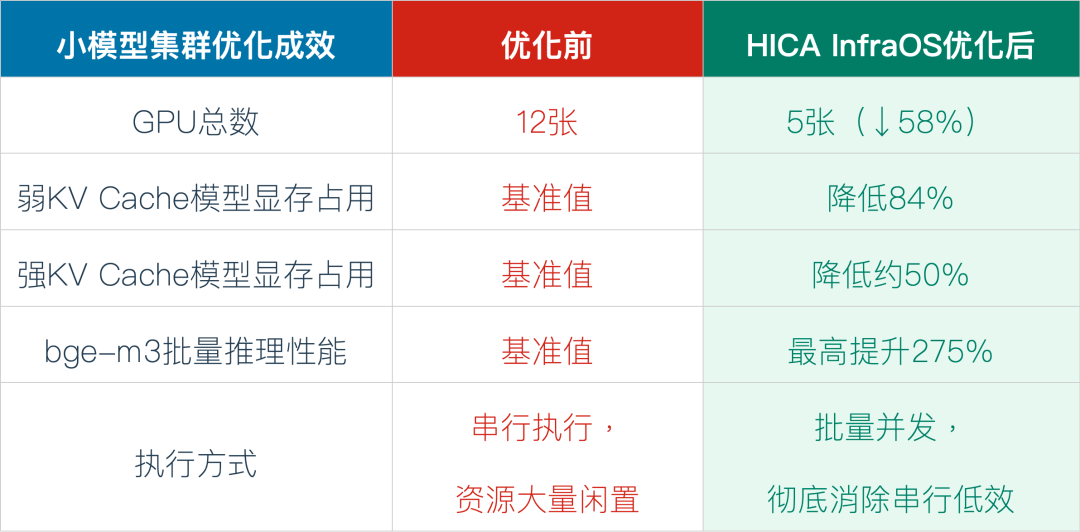
与此同时,HICA InfraOS 还通过精细化显存治理释放出足够的显存余量,使调度层得以将多个请求合并,让该集团整体的推理架构实现从串行到并发批量处理的升级,在不增加任何硬件的前提下,GPU的有效计算时间大幅提升,小模型集群GPU总用量降低58%,吞吐量反而显著跃升。
▲旧方案:单请求串行处理(左)→HICA InfraOS:异步并发+批量推理(右)
价值升维:
实时监控大盘构建看得见的掌控感
如果说前面四步——硬件解锁、智能调度、推理加速、显存治理——共同构成了HICA InfraOS的“算力优化引擎”。而“实时监控大盘”,则是建立在这四步之上的另一层价值:让每一项优化都有数据可查、有指标可验,有效支撑了该集团内部运维团队从“凭感觉管理”转向“用数据决策”,实现算力治理的闭环。
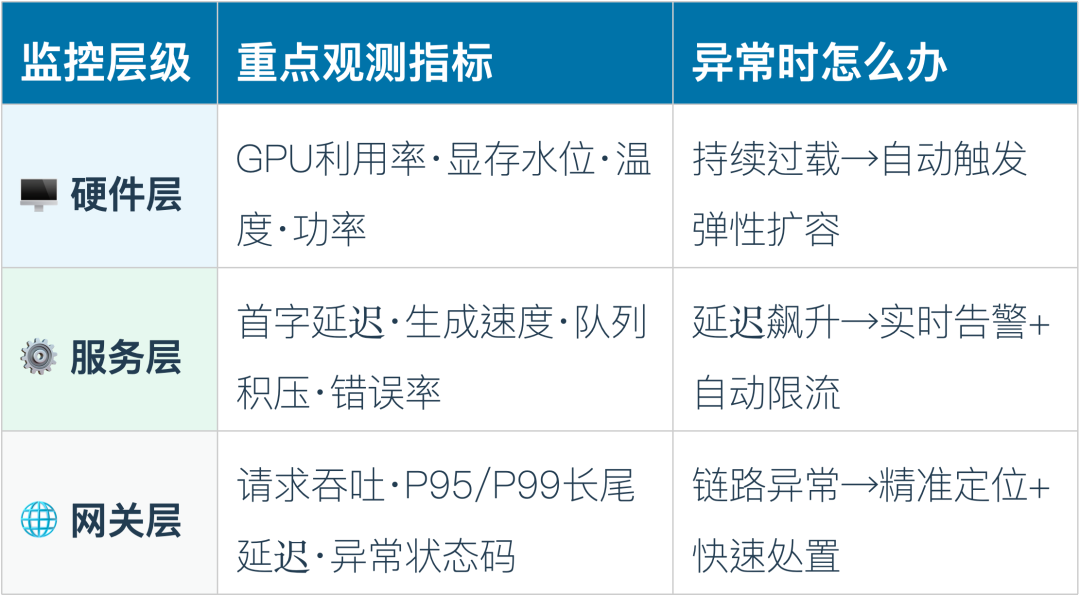
而更重要的是,在这个过程中,HICA InfraOS内置完整的可观测体系,真正做到了“让运维团队无需写一行查询语句,就能实时掌握每一个关键指标”。
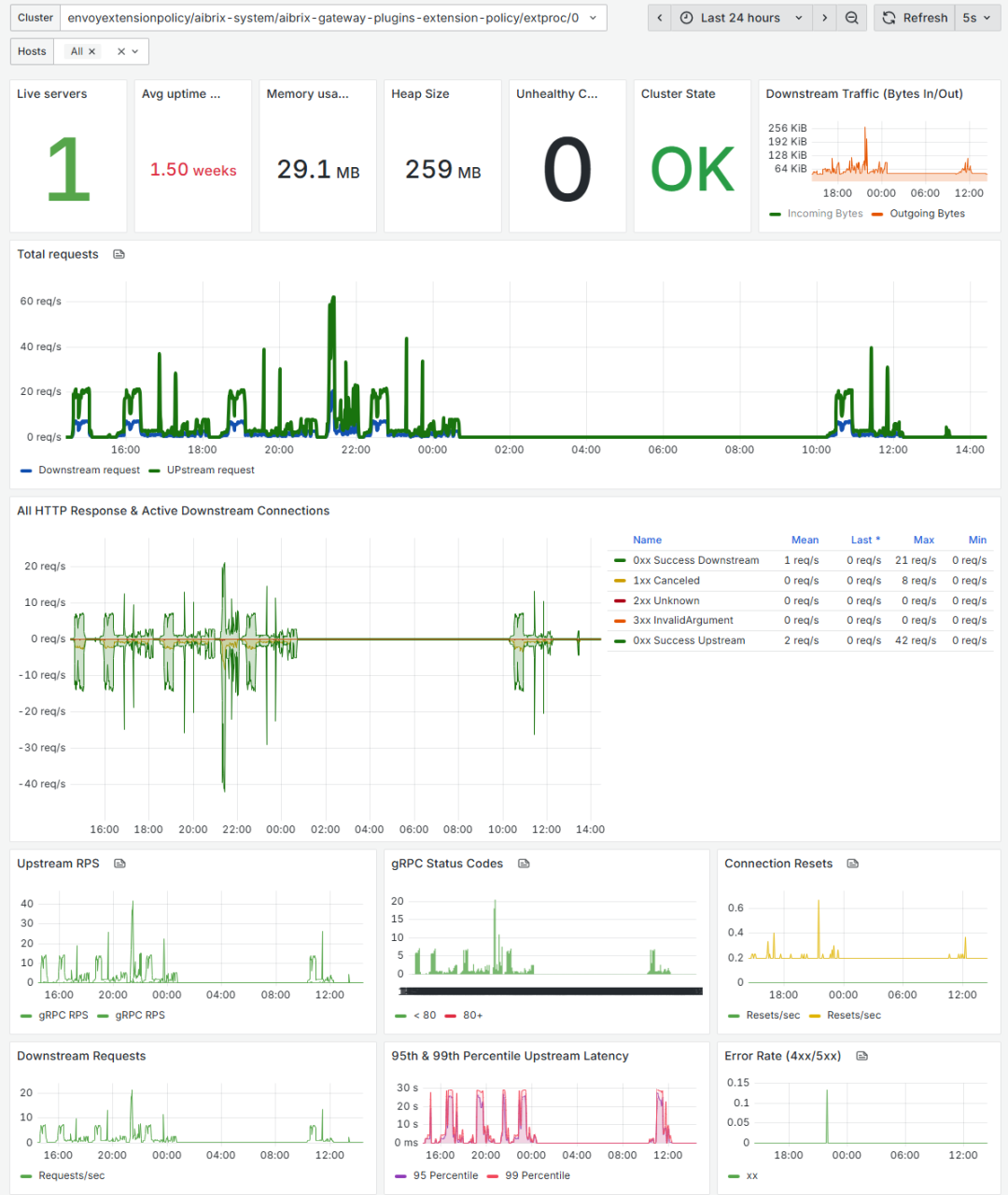
服务级监控:
延迟/队列/错误率
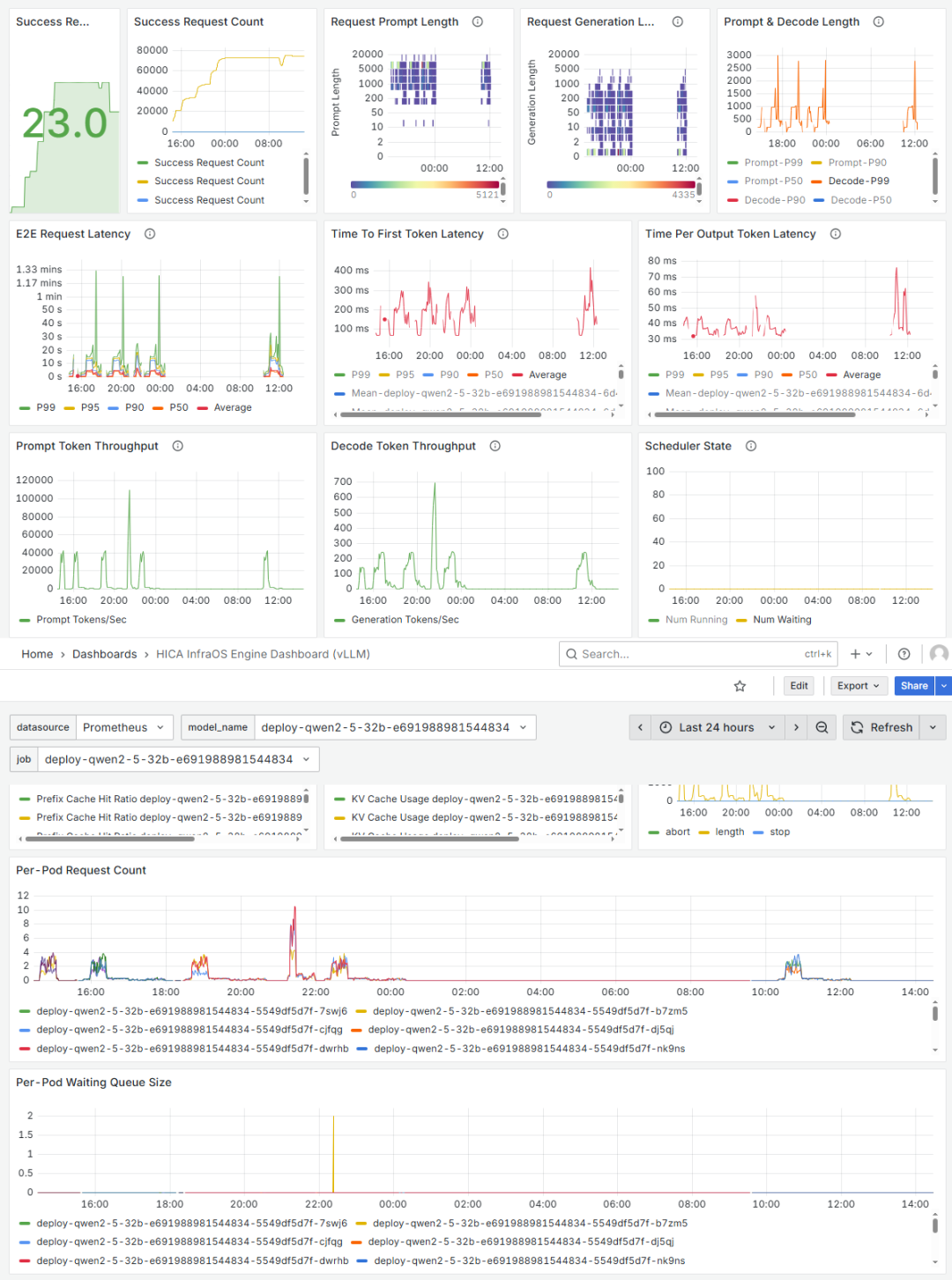
硬件级监控:
GPU/显存/温度
三级监控体系:从硬件到业务,无盲区覆盖
这不是一个项目,
这是一种能力
当前,算力紧缺已成为行业常态。企业AI的核心矛盾,正在从“有没有算力”转向“能不能用好算力”。
而神州数码HICA InfraOS给出的答案是:动态调度、智能缓存、优先级保障、精细化资源分配——让每一张GPU都被高效利用,实现业务体验与资源效益的双重最优。
我们相信,在算力革命的浪潮中,真正决定企业AI竞争力的,不是GPU数量的堆砌,而是资源利用的效率与架构迭代的速度,“以软件定义硬件”、“以效率优化成本”或许是解决企业现实算力困局的“更优解”。